Feature #2747
open
Make StreamFace processing time constant regardless of object size
0%
Description
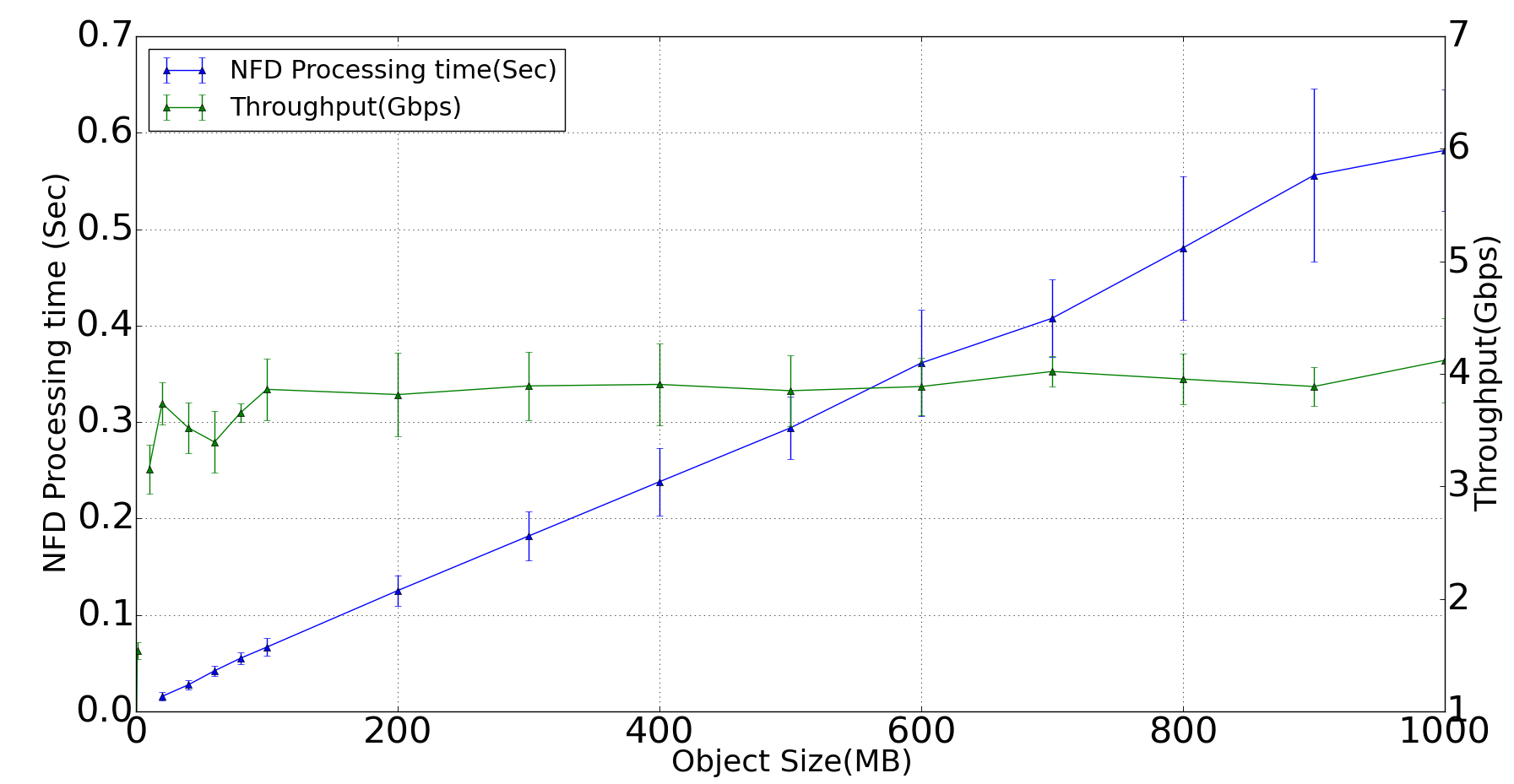
Right now, nfd processing time grows linearly with the object size (see attached picture) when using TCP face.
This happens because there is a buffer allocation and copy in the stream face. It takes about 0.6 seconds to process a 1GB object.
isOk = Block::fromBuffer(m_inputBuffer + offset, m_inputBufferSize - offset, element);
Not sure about the best way to address this or how hard it's to implement zero copy.
Files
{kind=link}
 Updated by Davide Pesavento almost 11 years ago
Updated by Davide Pesavento almost 11 years ago
- Subject changed from Make NFD processing time constant regardless of object size to Make StreamFace processing time constant regardless of object size
- Category set to Faces
- Start date deleted (
04/12/2015)
Some time ago I proposed to use boost::circular_buffer in StreamFace instead of the current linear array, in order to avoid copying the data. Asio already supports scatter/gather operations, so this change would be almost transparent for the face itself. As far as I know, the only problem is that ndn-cxx doesn't support reconstructing a Block from a non-linear buffer.
 Updated by Alex Afanasyev almost 11 years ago
Updated by Alex Afanasyev almost 11 years ago
Not an answer, but rather a stupid question. Is there still a point of increasing the "packet" size if the throughput cap is basically achieved with a very small packet size?
 Updated by Junxiao Shi almost 11 years ago
Updated by Junxiao Shi almost 11 years ago
- Target version set to Unsupported
This is Unsupported because ndn-cxx doesn't support packet size over 8800 octets.
MTU is there for a reason. Don't abuse it by setting a large packet size limit.
If you just want to make it consistent, add a delay for packets that take shorter time.
That would be a correct, although not ideal, solution.
A fundamental issue with StreamFace zero-copy by circular buffer (or, more generally, storing multiple incoming packets in the same buffer) is: packet lifetime differs by each packet.
Suppose there are three consecutive incoming Data packets, the first and third are cached by ContentStore, but the second is dropped because it's unsolicited.
The buffer space for the second Data packet is now available, but it can't be reused or deallocated until the first and third Data packets are evicted from ContentStore.
 Updated by susmit shannigrahi almost 11 years ago
Updated by susmit shannigrahi almost 11 years ago
We found that the max throughput is reached when packet size is ~300MB . 8800 is very small, even with pipeline.
The MTU needs to be <9000 (or <1500), not sure if NDN data packets need to be that small, specially for cases such as high speed transfer over dedicated links.
Alex, no, there is no point increasing the packet size after a certain point. The graph was part of a experiment we did to see what that size is.
Updated by Davide Pesavento almost 5 years ago
- Target version deleted (
Unsupported)