Bug #2413
closed
Remote prefix registration: prefix is not registered if app starts before HUB connection
100%
Description
Steps to reproduce:
ndnsec-keygen -n /ndn/edu/arizona/user1ndnpingserver /ndn/edu/arizona/user1nfdc register /localhop/nfd udp4://hobo.cs.arizona.edu(ornfdc register /localhop/nfd/rib udp4://hobo.cs.arizona.edubefore #2412 is resolved)
Expected: ndn:/ndn/edu/arizona/user1 is registered after establishing HUB connection
Actual: redo 0 registration when new Hub connection is built
Files
{kind=link}
{kind=link}
 Updated by Alex Afanasyev over 11 years ago
Updated by Alex Afanasyev over 11 years ago
- Priority changed from Normal to Urgent
Please submit fix tomorrow. We need this issue to be resolved before Wednesday (be part of the upcoming 0.2.1 release).
 Updated by Junxiao Shi over 11 years ago
Updated by Junxiao Shi over 11 years ago
This issue shouldn't be Urgent.
Operator can always workaround by starting apps after HUB connection.
(on my node, it takes just a sleep 2)
 Updated by Yanbiao Li over 11 years ago
Updated by Yanbiao Li over 11 years ago
- Status changed from New to Code review
- % Done changed from 0 to 90
Updated by Junxiao Shi about 11 years ago
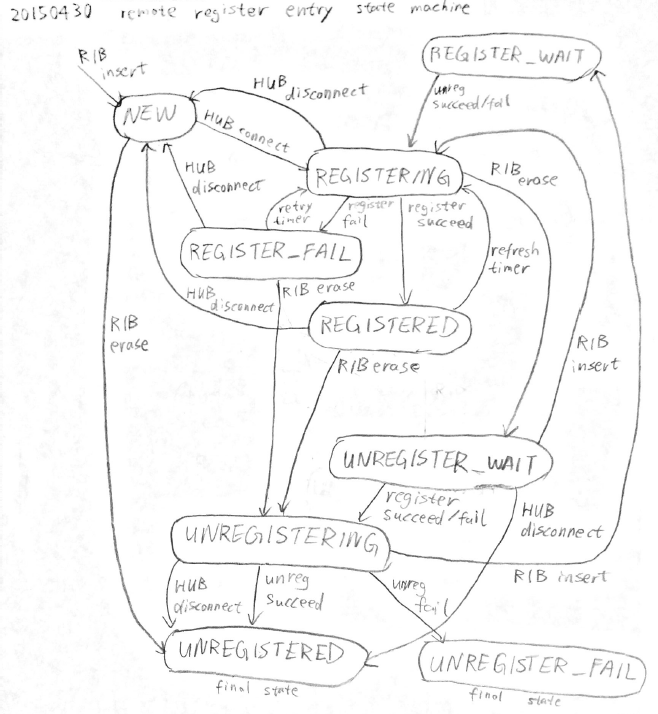
- File remote-register-state-machine_20150430.png remote-register-state-machine_20150430.png added
- Priority changed from Urgent to Normal
The design in note-4 adopts some kind of state machine, but the state transitions are incomplete.
In particular, it doesn't specify what happens if HUB is disconnected during a command, and what happens if RIB entry is erased during registration.
In any case, the state machine and state transitions should be presented as a figure in the document, not just text.
Another problem is: even if the last registration command was unsuccessful, it's still necessary to send unregistration command in certain cases.
In particular, if the last registration command was timed out, the registration was probably successful on the HUB.
To keep it simple, I would always send unregistration command.
Please have a look at my state machine design.
There is one state machine per connected HUB.

Updated by Yanbiao Li about 11 years ago
Thanks for junxiao's comments.
Start from the state machine presented in note-5, I make some modifications according to my implementation.
Updated by Junxiao Shi about 11 years ago
note-6 argues that REGISTER_WAIT can be merged into REGISTERING, but this is incorrect.
REGISTER_WAIT can be entered after this sequence:
- App registers /A, so laptop sends a remote registration command, state becomes REGISTERING.
- The remote registration command succeeds, state becomes REGISTERED.
- App quits, so laptop sends an unregistration command, and state becomes UNREGISTERING.
- Before the unregistration command completes, app starts and registers /A.
It's incorrect to immediately send registration command and enter REGISTERING in this situation, because the unregistration command in step 3 may arrive after the registration command, and cause the newly registered entry to be erased.
Instead, the laptop needs to stay in REGISTER_WAIT state until the unregistration command either succeeds or fails.
Updated by Yanbiao Li about 11 years ago
I detail the example in the "incorrect" case as follows:
t0: send reg_cmd_1 for entry_A; entry_A is inserted into the registered list.
t1: get successful response of reg_cmd_1
t2: send unreg_cmd_1 for entry_A; entry_A is erased from the registered list.
t3: send reg_cmd_2 for entry_A; entry_A is inserted into the registered list.
t4: reg_cmd_2 succeeds on the hub
t5: unreg_cmd_1 succeeds on the hub
t6: get successful response of reg_cmd_2; entry_A is associated with a refresh event.
t7: get successful response of unreg_cmd_1
(where t0 < t1 < t2 < t3 < t4 < t5 < t7, t4 < t6)
This case is identified as "unregistered a registering entry".
for the design in note-5:
the above case will not happen. reg_cmd_2 is suspended till get the response of unreg_cmd_1 (t7 < t3, where d1=|t3-t7| is very small)
for the design in note-6:
reg_cmd_2 will be resend after t6 due to the refreshing event. there must be some t3' (for resending reg_cmd_2) such that t7 < t3'. This can also ensure entry_A be successfully registered on the hub after unregistration. The only problem is that d2=|t3'-t7| may be greater than d1. How big will d2 be depends on the setting of refresh interval.
design in note-6 can also be improved:
actually, we can easily recognize the "unregistered a registering entry" case in onUnregSuccessful. Based on the design in note-6, if the unregistered entry still exists in the registered list, it must be registered again (after being unregistered). In this case, we can cancel the refresh event (if it's scheduled) and start remote registration for this entry (t3'') immediately, where d3=|t3''-t7| may be more or less the same as d1.
Summary:
design in note-5 can avoid the above case at the cost of a complicated state machine, which is more complicated for both implementing now and extending in future.
design in note-6 has a very simple state machine, but can not avoid the above case. However, that case may not bring in a big problem and the problem can be easily resolved based on the design.
Updated by Junxiao Shi about 11 years ago
When you are already using a state machine, it's better to make every distinct state explicit, and not to have any implicit/hidden states.
Otherwise, the state machine is hardly understandable.
design in note-5 can avoid the above case at the cost of a complicated state machine, which is more complicated for both implementing now and extending in future.
Please prove that a state machine with more states is harder to extend than a state machine with implicit/hidden states.
Updated by Yanbiao Li about 11 years ago
I think reducing unnecessary states and transitions is the basic rule for optimizing sate machines.
For a state machine with more states, people have to know more state definitions and transition logics to understand the whole picture. Also, we have to care about more relationships when inserting a new state.
Back to this case, I do not think there are some states from note-5 hidden in note-6. They have different state definitions (even the state with the same name). The state machine in note-6 describes the processing mechanism completely. It's smaller because the mechanism is different. (note-6 and note-8 discusses this mechanism in detail)
So, I prefer to use a smaller state machine unless the represented mechanism should not be adopted.
Updated by Junxiao Shi about 11 years ago
Again, note-6 state machine contains implicit states, which should be avoided. Every state must be explicit.
Updated by Yanbiao Li about 11 years ago
So, I guess that you agree on the processing mechanism in note-6, just excluding the state machine.
When a remote unregistration is ready, the corresponding entry is erased from the registered list at once and the command is sent out if feasible (why and how this mechanism works are discussed in detail in note-6). This is the key point why I can use a smaller state machine.
When an entry has been erased (dead), Why we need further states to describe a "dead" entry?
In the state machine described in note-6, the state RELEASED (when the entry is erased) is the terminate state, after which there is no other states. So UNREGISTER_WAIT, UNREGISTERING, UNREGISTERED are not implicit but non-existent according to the above mechanism.
Updated by Junxiao Shi about 11 years ago
Again, see note-7 for the flaw in note-6 state machine.
Updated by Yanbiao Li about 11 years ago
Junxiao Shi wrote:
note-6 argues that REGISTER_WAIT can be merged into REGISTERING, but this is incorrect.
REGISTER_WAIT can be entered after this sequence:
- App registers /A, so laptop sends a remote registration command, state becomes REGISTERING.
- The remote registration command succeeds, state becomes REGISTERED.
- App quits, so laptop sends an unregistration command, and state becomes UNREGISTERING.
- Before the unregistration command completes, app starts and registers /A. It's incorrect to immediately send registration command and enter REGISTERING in this situation, because the unregistration command in step 3 may arrive after the registration command, and cause the newly registered entry to be erased. Instead, the laptop needs to stay in REGISTER_WAIT state until the unregistration command either succeeds or fails.
please see my detail explanation in note-7.
here, I summarize how my design works for the above case.
- App registers /A, so laptop sends a remote registration command, state becomes REGISTERING.
- The remote registration command succeeds, state becomes REGISTERED.
- App quits, so laptop sends an unregistration command, and state becomes (UNREGISTERING)-->RELEASED(the entry is erased).
- Before the unregistration command completes, app starts and registers /A, state becomes REGISTERING.
what you worry about is the following situation:
5.remote registration command succeeds, send out response x.
6.unregistration command completes, send out response y.
if x arrives earlier than y:
7(a). response x arrives, state becomes REGISTERED.
8(a). response y arrives, it's detected that "unregistered a registered entry", we re-send registration, states becomes REGISTERING.
if y arrives earlier than x:
7(b). response y arrives, it's detected that "unregistered a registering entry", we re-send registration, keep as REGISTERING.
8(b). response x arrives, state becomes REGISTERED, schedule a refresh event.
9(b). Since the timeout of registration command is smaller than refresh_interval (the default setting is 10s VS. 300s), 7(b) can get a response (succeed, fail or timeout) before the refresh command is sent out. Then, the refresh event scheduled in 8(b) will be replaced. And the state will keep as REGISTERED or change to REGISTERING according to the response.
I think everything works based on the design in note-6 in which the state machine is smaller.
Updated by Junxiao Shi about 11 years ago
The problem with note-14 is: when the state machine enters RELEASED and is terminated, the unregistration command is still pending, and some implicit state is needed in order to process the response.
Updated by Yanbiao Li about 11 years ago
I don't think some implicit stats are required to process the response. We only need to check whether the unregistered entry exists in the registered list.
Actually, there are in total 4 cases:
1/ unregistration succeeds, the corresponding entry does not exist.
2/ unregistration succeeds, the corresponding entry still exists.
3/ unregistration fails, the corresponding entry does not exist.
4/ unregistration fails, the corresponding entry still exists.
In case 1, nothing need to do, it's a "expected" result.
In case 2, the corresponding entry should have been erased before sending out unregistration command, but it still exists. This means it's inserted again by another registration request. In this case, we may have unregistered a registering entry. So, we should set its state to REGISTERING and re-send the registration command.
In case 3, we can either do nothing or re-try unregistration. In current design, we do nothing in this case.
In case 4, nothing need to do. Although we fail to unregister this entry, there is another request to register this entry again.
Updated by Junxiao Shi about 11 years ago
When starting an unregistration command, in order to process its success/failure result, a bound function is passed to the Controller.
One or more parameters bound to this callback function become an implicit state.
Updated by Yanbiao Li about 11 years ago
yes, the control parameters (contains the name of the corresponding entry) and the command options of this unregistration command are bounded to the callback, but not the corresponding entry itself. To process the response, we need nothing about this entry except its existence, which can be simply detected by the name (ControlParamters::getName()). So, I don't think we need keep this entry to process response.
Updated by Junxiao Shi about 11 years ago
I agree with note-18.
Please update the state machine to reflect note-16 description.
An event on a "non-existent entry" should be represented as a transition from RELEASED state.
Updated by Yanbiao Li about 11 years ago
by "An event on a "non-existent entry" should be represented as a transition from RELEASED state.", do you mean that if we are going to operate a "non-existent entry", it should be "resurrected" first trough some transition from RELEASED?
In my opinion, a RELEASED entry not only is "non-existent" in logic but also is indeed erased from the list, but the unregistration command may have not completed yet. Any further operations are just toward a new entry that by chance has the same name. The only thing we should take care of is that an unregistered entry may still "exists" (in fact, this is a new entry with the same name) when the unregistration command gets a successful response. In this case, a transition from REGISTERED to REGISTERING may be triggered (as discussed in note-14 and note-16).
Updated by Junxiao Shi about 11 years ago
Yes, the entry is indeed erased in RELEASED state, and I understand that.
A transition from RELEASED state indicates the processing when some event happens but an entry with that prefix does not exist.
Look at TCP state machine: CLOSED is the logical state when a state machine is not in the connection table.
RELEASED here serves the same purpose as TCP's CLOSED.
Updated by Yanbiao Li about 11 years ago
Due to my understanding, TCP state machine describes the states a TCP device will be and the transitions between those states. When a TCP device goes into the CLOSED state, the device itself still exists and will be prepared for another connection. So the transitions from CLOSED are required to "resurrect" that device. But in our case, the entry is really erased and will not be "resurrected" any more. On the other hand, CLOSED state is the default and start state of TCP state machine, which corresponds to the NEW state in our state machine.
Updated by Junxiao Shi about 11 years ago
Then NEW and RELEASED should be merged.
The merged state is both initial and final state.
When an entry does not exist, it's logically seen as in NEW state.
The four cases in note-16 would be:
- state=NEW, event="unregistration success", action=none, next=NEW
- state=REGISTERING, event="unregistration success", action="send register command", next=REGISTERING
state=REGISTERED, event="unregisteration success", action="send register command", next=REGISTERING - state=NEW, event="unregistration failure", action=none, next=NEW
- state=REGISTERING, event="unregistration failure", action=none, next=REGISTERING
state=REGISTERED, event="unregistration failure", action=none, next=REGISTERED
The above is a precise description of note-16 in this state machine.
However, there's a problem: if an unregistration failure is a timeout, the unregistration may have been successful on the gateway router.
This event needs to be distinguished from having received an error code, and follow another set of transitions similar to those in unregistration success: action="send registration command", next=REGISTERING.
Updated by Yanbiao Li about 11 years ago
I don't think NEW and RELEASED should be merged. In TCP state machine, when a connection is closed, the subjective, namely the TCP device, still exits and can be involved in later connections. But in our case, when an entry is about to be unregistered, it is erased (goes into the RELEASED state) and thus does not exist any more (how and why this mechanism works are discussed in detail in note-14 and note-16). The only case an entry should go back to the NEW state is that the connectivity is lost. In this case, the entry still exists and can be involved in later operations.
In addition to normal transitions, we should also take care of 2 cases:
- registration response is back, but the entry does not exist (is erased when is going to do unregistration).
- unregistration response is back, but the entry still exists (is inserted when is going to do a new registration).
Following are the detail cases:
1.1 entry does not exist (state=RELEASED), event="registration succeeds", action="do unregistration"
1.2 entry does not exist (state=RELEASED), event="registration fails", action="no action" (another option is doing unregistration as well if it is just timeout. Both are mentioned in note-6, we should make a decision.)
2.1 state=REGISTERING/REGISTERED, event="unregistration succeeds", action="do registration", state=REGISTERING
2.2 state=REGISTERING/REGISTERED, event="unregistration fails", action="no action" (because the retry event is already scheduled to do registration again). Here we also have another option that doing registration as well and switch the state to REGISTERING if it is just timeout. we also should make a decision.
Updated by Junxiao Shi about 11 years ago
note-24 seems correct. Please produce a document of the complete state machine. It should show all transitions and actions. If an event doesn't trigger any action or state transition, draw an arrow pointing back to the same state.
Updated by Yanbiao Li about 11 years ago
- File state machine.pdf state machine.pdf added
We should make decisions for following issues:
When register fails, shall we take into account that it may succeed on the remote end if the failure reason is timeout.
When unregister fails, shall we take into account that it may succeed on the remote end if the failure reason is timeout.
Updated by Junxiao Shi about 11 years ago
- File 20150627173828.PNG 20150627173828.PNG added
Reply to note-26:
The state machine is missing some actions and transitions, shown in red.

There are two design choices in defining the action/nextstate from REGISTERING/REGISTERED upon unregister succeed/fail:
- do registration; REGISTERING
- set retry timer; REGISTER_FAIL
I'm unsure which choice is better.
- When register fails, shall we take into account that it may succeed on the remote end if the failure reason is timeout.
- When unregister fails, shall we take into account that it may succeed on the remote end if the failure reason is timeout.
Ideally we should, but how would the state machine be look like?
Updated by Yanbiao Li about 11 years ago
Reply to note-26:
The state machine is missing some actions and transitions, shown in red.
Actually, the "missed" cases you mentioned above are not missed in my view. I just draw the state machine in my preferred way:
1. I will not draw any "transition" from one state to itself with out triggering any actions.
When an event happens, the state will keep the same and no action will be triggered, I do not think there is a transition. But I do not mind to add a entry in the event-action table that indicates this is a valid event anyway.
All red labels in the "RELEASED" column, the third red label in the "REGISTERED" column and the second and the third red labels in the "REGISTER_FAIL" column are all in this case (8 out of 16 red labels).
2. I will not label the detail action if this is a "regular" transition that from one state to another one.
The state machine is to describe every valid transition with its source state, destination state and the event that triggers this transition.
The red label in the "NEW" column, the two red labels in the "REGISTERING" column, the first and the last red labels in the "REGISTERED" column and the "REGISTER_FAIL" column are all in this case (7 out of 16 red labels)
3. I will label the the detail action for the transition that from one state to itself to indicate that this transition does make sense.
There are two design choices in defining the action/nextstate from REGISTERING/REGISTERED upon unregister succeed/fail:
- do registration; REGISTERING
- set retry timer; REGISTER_FAIL
I'm unsure which choice is better.
If unregister fails, it falls into the two issues below. By contrast, if unregister succeeds, I think we should do registration directly (the state will become REGISTERING) to recover the unexpected unregistration in time. So the second red label in the "REGISTERED" column will be "do registration; REGISTERING", which falls into point-2 described above (1 out of 16 red labels, so all 16 "missed" cases are not missed actually).
The only "missed" thing is such a event-action table. I have it and write codes according to it but did not submit it in note-26 (if required, I can submit it along with the state machine).
- When register fails, shall we take into account that it may succeed on the remote end if the failure reason is timeout.
- When unregister fails, shall we take into account that it may succeed on the remote end if the failure reason is timeout.
Ideally we should, but how would the state machine be look like?
Firstly, we should divide the events register fail and unregister fail into 4 events: register fail with timeout, register fail with other reasons except timeout; unregister fail with timeout; unregister fail with other reasons except timeout.
Secondly, above 4 events play the same roles as original register fail and unregister fail except two cases:
- state=RELEASED, event=register fail with timeout. In this case, do unregistration.
- state=REGISTERED/REGISTERING (there is a typo in note-26 that the event above the transition from REGISTERING to itself should be unregister succeed but not unregister succeed / fail), event=unregister fail with timeout. In this case, switch to state REGISTERING and do registration again (or switch to REGISTER_FAIL and set retry timer)
Updated by Junxiao Shi about 11 years ago
Please show the complete state machine, including ALL legal transitions and actions, as either a table or a graph (not both).
Any unlisted transition is deemed impossible, and shall cause an assertion error in code.
Updated by Junxiao Shi about 11 years ago
- Status changed from Code review to In Progress
- Target version changed from v0.3 to v0.4
This issue is not "Code Review" because design is incomplete.
Updated by Yanbiao Li about 11 years ago
A transition means there is indeed some change: either a state switch or a triggered action.
If an event does not trigger any state switch or action, how can it trigger a "transition"?
It's obviously possible that some event happens but do not require us to do anything on its happening (e.g., there is no transition associated with its happening). Why it should be treated as an error?
The graph is used to describe all valid transitions more clearly. The event-action table is used to describe all valid events including that does not trigger transitions and the detail actions associated with valid transitions. The graph and the table have different effects and using both of them can make the design clearer and easier to understand. I do not see this rule anywhere else that "you can use either a graph or a table but not both".
Updated by Junxiao Shi about 11 years ago
Reply to note-31:
A transition does not necessarily perform any action or cause the state machine to enter a different state.
The turnstile example on Wikipedia - Finite-state machine page shows a state machine, where two of four transitions have their next state equal the current state, and have no output.
A finite-state machine may be represented with State/Event table, UML state machine, SDL state machine, etc
(see Wikipedia - Finite-state machine ).
You shouldn't have both a table and a graph, because one of the following will happen:
- The table and the graph do not represent the same state machine. In this case, the design is conflicting with itself.
- The table and the graph represent the same state machine, which means they have the same transitions (including those whose next state equals current state and have no output/action). In this case, one of the two representations is redundant.
Updated by Yanbiao Li about 11 years ago
A transition does not necessarily perform any action or cause the state machine to enter a different state.
The turnstile example on Wikipedia - Finite-state machine page shows a state machine, where two of four transitions have their next state equal the current state, and have no output.A finite-state machine may be represented with State/Event table, UML state machine, SDL state machine, etc
(see Wikipedia - Finite-state machine ).
You shouldn't have both a table and a graph, because one of the following will happen:
- The table and the graph do not represent the same state machine. In this case, the design is conflicting with itself.
- The table and the graph represent the same state machine, which means they have the same transitions (including those whose next state equals current state and have no output/action). In this case, one of the two representations is redundant.
I guess you know character trie (can be treated as a special DFA) and its transition-table description as well as its DAT description. There, transition-table and DAT are different forms of the same thing. There is no conflict between them and each of them has its own advantages (thus can not be treated as redundant). Actually, transition-table can describe the "shape" of the trie clearly, while DAT just cares about the input character will trigger state switch and thus can reduce sharply memory cost. If both their advantages are required in some case you can use them both.
As for our case, a transition-table (event-action table) describes all events and corresponding actions (or no action). Actually, it describes what there are. If some event will not trigger any state switch or action, we will not do anything in response to it (namely no codes will be written for it). So I define a transition in the graph I used that there will be either a state switch or triggered action associated. Actually, the graph I used describes what we deal with in essential. Yes, use the transition table is enough to describe the state machine of maintaining registered entries. But using the additional graph can clearly describe the cases we should care about where we should write some codes. Note that we are not discussing a application of state machine, we are discussing the mechanism of maintaining registered entries. If we can make the description both rigorous and easily understood, why not?
Updated by Junxiao Shi about 11 years ago
Reply to note-33:
The graph, when not including state+input pairs that do not arrive to a different next state, is unable to indicate whether such a missing state+input pair is designed to be stay in the same state with no action, or it's deemed impossible.
The former requires no code other than a comment, and the latter should have an assert(false) to ensure it logically cannot happen.
Updated by Yanbiao Li about 11 years ago
The graph, when not including state+input pairs that do not arrive to a different next state, is unable to indicate whether such a missing state+input pair is designed to be stay in the same state with no action, or it's deemed impossible.
The former requires no code other than a comment, and the latter should have an assert(false) to ensure it logically cannot happen.
I think an impossible case is the one that is unable to happen.
I guess what you mean is similar to the invalid inputs of the FSM that will terminate the traversing process. This case can happen but is not valid and continuously traversing in this case is indeed wast of time.
Note, in our case, that all input events (except "rib insert", "rib erase", "hub connect", "hub disconnect") are part of output events or resulted by output events, when they will happen can be completely controlled within the proposed mechanism (we know which are possible and which are impossible). For the rib events and hub events, we are not able to control them in the proposed mechanism. So they can happen in any cases from the point of view of remote registrator. Even though some unexpected case happens, we can just stay at the same state (and do nothing else) to tolerate the "failure" (it will do no harm to the maintaining of registered entries), rather than terminate the system.
Updated by Junxiao Shi about 11 years ago
Reply to note-35:
All IMPOSSIBLE cases in note-27 table are indeed logically impossible to happen.
When one of them happens, it means there's a logical error in the program, so that it's correct to cause an assertion failure.
Updated by Yanbiao Li about 11 years ago
All IMPOSSIBLE cases in note-27 table are indeed logically impossible to happen.
When one of them happens, it means there's a logical error in the program, so that it's correct to cause an assertion failure.
For any of those IMPOSSIBLE cases in note-27 table, I think either there is no chance it will happen or we can just tolerate it by staying at the same state and doing nothing else.
Could you please point out some case that indeed has chance to happen and can not be tolerated, I'm very happy to amend the mechanism then.
Updated by Junxiao Shi about 11 years ago
Reply to note-37:
All IMPOSSIBLE cases in note-27 table have no chance to happen - unless there's a logical error, which would be caught by the assertion.
Updated by Yanbiao Li about 11 years ago
If all expected cases work properly (I think this can be ensured by unit test), there is no obvious logic error in the codes (I think this can be ensured by code review), and the potential unexpected cases can be tolerated without any harm to the whole system , I do not think we have to do anything else.
Take the following case as an example: "refresh_timer" happens but the current state is "RELEASED".
This case will not happen due to the processing logic, because a refresh timer will only be set up after registration succeeds where the state is "REGISTERED".
However, if this case indeed happens due to some "crazy" reason that I accidentally set up the refresh timer at other place (but if I really do this, the unit test may not pass because it may cause the retry_timer be released) or that there is some unexpected error in the event management module (outside this mechanism so that can is not controllable in this mechanism). We can easily tolerate this unexpected case by checking the current state. If it is "REGISTERED", we do registration. Otherwise, do nothing. I do not think this will cause any problem.
Updated by Junxiao Shi about 11 years ago
Reply to note-39:
Any unexpected case is a serious logical error. If for whatever crazy reason one happens, the program (when built as debug) deserves to crash with an assertion failure.
You should be confident to put in assertions for impossible cases, because they can never be triggered if logic is correct.
Code review cannot prove the logic is correct, unless assertions are in place for all impossible cases.
Updated by Yanbiao Li about 11 years ago
Any unexpected case is a serious logical error. If for whatever crazy reason one happens, the program (when built as debug) deserves to crash with an assertion failure.
Yes, it is a logical error, but what I claim here is the mechanism itself can tolerate such an error. So I think we do not need to set up some serious action (such as crash) to handle it.
You should be confident to put in assertions for impossible cases, because they can never be triggered if logic is correct.
Code review cannot prove the logic is correct, unless assertions are in place for all impossible cases.
Yes, of course. I just do not think it's required to crash with some error that can be tolerated by the mechanism actually. I never mind to log out something for debug or other purpose. This is only to make the implementation more robust and more readable but not to improve the design.
I do not think we should take it into consideration that the developer will not obey the design in implementation accidentally when we are working out the design, except such improper implementation will prevent the design from working properly (e.g. can not be tolerated). In that case, we should either set up some solution in the design or warn the developer with the serious results. For this design, we just point out which cases are impossible (they are indeed impossible from the point of view of design), leaving how these cases be dealt with an implementation issue (you can log out in these cases for debug, but you do not have to do anything else to ensure the whole design work properly).
To describe this design, in addition to a transition-table (event-action table) that includes everything, I will still draw the least information in a graph that may help others know how the mechanism works in a direct and easy way. If you think current information presented in the graph may confuse others, I can write a note there: the cases not drawn in this graph are either impossible cases or the ones are possible but require no treatment.
Updated by Junxiao Shi about 11 years ago
Again, impossible cases need assertions: this is exactly what assertions are intended for.
An impossible case cannot be tolerated under any circumstance because it is a serious programming error.
It's difficult to prove the code can behave as intended unless it's protected by assertions in impossible cases.
And remember: assertions are enabled only in debug mode, so they won't cause a crash in production environment.
Updated by Yanbiao Li about 11 years ago
Again, impossible cases need assertions: this is exactly what assertions are intended for.
An impossible case cannot be tolerated under any circumstance because it is a serious programming error.
It's difficult to prove the code can behave as intended unless it's protected by assertions in impossible cases.
And remember: assertions are enabled only in debug mode, so they won't cause a crash in production environment.
Again, how to deal with impossible cases is a implementation issue, whatever you like to do in debug mode is not a mandatory part required to be defined in the design.
Updated by Junxiao Shi about 11 years ago
Reply to note-43:
In the design, distinguish between cases that are impossible, and cases that are correct but should not trigger any action or change to a different state.
In the implementation, put assertions on impossible cases.
Updated by Yanbiao Li about 11 years ago
Last issue: if we decide to deal with the situation that when registration / unregistration get timeout failure it may succeeds on the remote end, we also have to make two things clear: 1) in which cases it's better to treat such situation as "successful" than "failure", 2) in which cases it's better to treat such situation as "failure" than "successful". Shall we do this now or finish #2413 first (this issue will not prevent current mechanism from working currently) and then deal with this issue later.
Updated by Junxiao Shi about 11 years ago
Reply to note-45:
This problem should be solved in this issue given you are already making a major change to the logic.
Whether to treat a timeout as "success on router" or "failure on router" depends on which situation is worse, ie. always assume the worst case scenario, and send additional command(s) to ensure the registration exists / does not exist on the router.
However, if "HUB disconnect" and then "HUB connect" happen, you may safely assume registration does not exist on the router.
Updated by Junxiao Shi almost 11 years ago
20150727 conference call discussed the problem in note-45.
We decide that it's okay to treat every timeout as a failure.
But this limitation should be mentioned in the design document.
Updated by Yanbiao Li almost 11 years ago
- File remote-state-matchine.pdf added
- File remote-transition-table.pdf added
Updated by Yanbiao Li almost 11 years ago
- File deleted (
remote-state-matchine.pdf)
Updated by Yanbiao Li almost 11 years ago
- File deleted (
remote-transition-table.pdf)
Updated by Yanbiao Li almost 11 years ago
- File remote-transition-table.pdf added
Updated by Junxiao Shi almost 11 years ago
The transition table in note-52 is mostly correct, except one problem:
"calling startRegistration()" is not an event. It's either part of another event that already appears above, or it should be listed with a different label that is indeed an event.
note-50 will be completely ignored because it either duplicates or conflicts note-52.
Updated by Yanbiao Li almost 11 years ago
When a rib insert event trigger a creation of new entry (at the initial status NEW), it will then goes into REGISTERING status as long as some preconditions are met, such as there is a connectivity and so on. But in this case, the startRegistration function is called which finally set the status of this entry to REGISTERING. So, I treat calling that function as an event triggering status switch from NEW to REGISTERING.
Besides, there may be another issue not covered. After registering some identity, it may be revoked. Then, we can not use it to sign the refresh / retry commands. In this case, I will erase the corresponding entry (--> RELEASED) and find another proper identity for the locally registered prefix. Do you think it's required to add an "identity revoked" event?
Updated by Junxiao Shi almost 11 years ago
Reply to note-54:
No. A function call is not an event.
In case a "rib insert" happens when there is already a HUB connection, two state transitions happen one after another:
- RELEASED, "rib insert", NEW, NONE
- NEW, "hub connect", REGISTERING, do registration
You may use a function call in the implementation, but it's not part of the state machine.
There is no such "identity revoked" event because PIB does not emit a signal when an identity is erased.
In case an identity has been revoked and no other certificate is available to do a registration, it would be an error.
Updated by Yanbiao Li almost 11 years ago
- File remote-state-matchine.pdf remote-state-matchine.pdf added
- File remote-transition-table.pdf remote-transition-table.pdf added
Updated by Junxiao Shi almost 11 years ago
remote-transition-table.pdf in note-56 is correct.
remote-state-matchine.pdf in note-56 will be completely ignored because it either duplicates or conflicts with the table.
Updated by Junxiao Shi almost 11 years ago
There is a dispute about the relation between RemoteRegistrationMetaInfo and RemoteRegisteredEntry.
Yanbiao's design, as my understanding, is:
RemoteRegisteredEntrycontains the state machine in note-56, and has a shared_ptr toRemoteRegistrationMetaInfo.RemoteRegistrationMetaInfocontains:- the signing identity, which is also the prefix to be registered on remote HUBs, found by doing a lookup in PIB with the RIB prefix
- the
CommandParametersandCommandOptionsused to send prefix registration commands - a back-off timer that controls how soon a failed registration should be retried.
- The
CommandParametersinsideRemoteRegistrationMetaInfohas itsCostfield unset before unregistration, and has itsCostfield set before registration. - The design is intended to support multi-HUB scenario, where each <remotely registered prefix, HUB> tuple has one state machine (and therefore
RemoteRegisteredEntry), but allRemoteRegisteredEntryobjects for a remotely registered prefix shares ownership of oneRemoteRegistrationMetaInfo.
This design is flawed.
- The distinction between
RemoteRegistrationMetaInfoandRemoteRegisteredEntryis unclear. - The design fails to support multi-HUB scenario. In particular, the back-off timer of a registration command is a per-prefix-HUB state, but it appears in
RemoteRegistrationMetaInfowhich is a per-prefix object.
Recommendation:
- Reduce
RemoteRegistrationMetaInfoto contain only: prefix being registered, signing identity, cost. Information carried inRemoteRegistrationMetaInfois static: it's determined only by local RIB and PIB, and is unaffected by the state of remote registrations. - Retain the
shared_ptr<RemoteRegistrationMetaInfo>inRemoteRegisteredEntryclass. - Move
CommandOptionsand back-off timer toRemoteRegisteredEntry.- The back-off timer is per-prefix-HUB, so it belongs to
RemoteRegisteredEntry. CommandOptionsspecifies the command prefix (such asndn:/localhop/hobo/nfdin #3142) of the HUB, so it needs to be per-prefix-HUB.
- The back-off timer is per-prefix-HUB, so it belongs to
- Construct
CommandParametersbefore sending each command, or cache it as part ofRemoteRegisteredEntry.
Updated by Yanbiao Li almost 11 years ago
Yanbiao's design, as my understanding, is:
RemoteRegisteredEntrycontains the state machine in note-56, and has a shared_ptr toRemoteRegistrationMetaInfo.
RemoteRegistrationMetaInfocontains:
- the signing identity, which is also the prefix to be registered on remote HUBs, found by doing a lookup in PIB with the RIB prefix
- the
CommandParametersandCommandOptionsused to send prefix registration commands- a back-off timer that controls how soon a failed registration should be retried. No, it's not a timer as it will not trigger any event directly, just records the current retryWaitTime based on back-off strategy, which is used by the RemoteRegistrator to schedule the next retry-event.
The
CommandParametersinsideRemoteRegistrationMetaInfohas itsCostfield unset before unregistration, and has itsCostfield set before registration.
No, 'Cost' filed is unset only when switching from RemoteRegistration to RemoteUnregistration, while it's set when switching from RemoteUnregistration to RemoteRegistration. A special case is that it will be unset before calling afterRibErase because the ControlParameters in MetaInfo is initialized to have the 'Cost' filed.
- The design is intended to support multi-HUB scenario, where each <remotely registered prefix, HUB> tuple has one state machine (and therefore
RemoteRegisteredEntry), but allRemoteRegisteredEntryobjects for a remotely registered prefix shares ownership of oneRemoteRegistrationMetaInfo.
We agreed very long-time ago current RemoteRegistrator is only for one-hub scenario.
But I also took multi-hub scenario into account when making this design.
So, I think most of current design can work in the multi-hub scenario.
This design is flawed.
- The distinction between
RemoteRegistrationMetaInfoandRemoteRegisteredEntryis unclear.
I have already explained what RemoteRegistrationMetaInfo is and how it works to you in gerrit.
1) RemoteRegistrationMetaInfo is just a collection of helper information for controlling the
registration/unregistration of each entry, to prevent same information (most fields of
ControlParameters, CommandOptions, etc) being copied everywhere and everytime.
2) when switching from unregistration to registration (this happens when unregistration succeeds
but the entry state is not in RELEASED), the Cost field of ControlParameters must be set.
By contrast, when switching from registration to unregistration (this happens when registration
succeeds but the entry state is in RELEASED), the Cost field of ControlParameters must be unset.
The sate machine design guarantees these two direction switches for the same entry happen sequentially.
So there will be no conflict resulted by this type of change.
3) when a registration fails, the current retryWaitTime should be recalculated. Since two attempts for the
same entry must be performed one by one, it's also guaranteed there is no conflict resulted by this type of change.
4) when a registration succeeds, the current retryWaitTime should be set back to the baseRetryWait.
For the same reason as mentioned above, there will be no conflict resulted by this type of change.
5) after hub connect, all entries should be registered again. And the current retryWaitTime for each entry
should be set to the baseRetryWait. It's also guaranteed there is no conflict resulted by this type of change.
I also have explained the why the RemoteRegisteredEntry keeps a pointer to RemoteRegistrationMetaInfo.
to let a registered entry keep a pointer to metaInfo is just a implementation choice to simplify the implementation.
In afterHubConnect, we need to do re-registrtaion for all entries. we have 3 choices to get required metaInfo for registration:
1) for each entry, we know the remotely registered prefix, we can scan the Rib to find out all rib entries that can be
covered by this prefix, and re-process these rib entries as just inserted.
2) keep a rib entry prefix in registered entry (many rib entries can be covered by a registered entry but only the first
one will trigger remote registration), and use this prefix to re-generate the metaInfo.
3) keep a pointer of metaInfo in registered entry so that we can directly use it.
In summary, RemoteRegistrationMetaInfo is designed to be used by the RemoteRegistrator to configure the
Registration/Unregistration command and to carry out the retry policy. It has no direct logic relation to RemoteRegisteredEntry. They can work separately. But during the lifetime of a RemoteRegisteredEntry, there is only one instance of RemoteRegistrationMetaInfo to configure its related Registration/Unregistration command.
- The design fails to support multi-HUB scenario. In particular, the back-off timer of a registration command is a per-prefix-HUB state, but it appears in
RemoteRegistrationMetaInfowhich is a per-prefix object.
No. See my comments on gerrit: "The registered entry is a RemoteRegisteredEntry, it should establish a one-to-one
relation to a remote registration but not a local rib entry". A RemoteRegisteredEntry is a per-hub-prefix object, so as
RemoteRegistrationMetaInfo that is used to configure the commands of a RemoteRegisteredEntry.
Recommendation:
- Reduce
RemoteRegistrationMetaInfoto contain only: prefix being registered, signing identity, cost. Information carried inRemoteRegistrationMetaInfois static: it's determined only by local RIB and PIB, and is unaffected by the state of remote registrations.
RemoteRegistrationMetaInfo is designed to configure the commands and to carry out the retry policy.
One local RIB prefix will lead to multiple registration commands (under different prefixes) to different hubs,
they must be configured and controlled by different RemoteRegistrationMetaInfo.
- Retain the
shared_ptr<RemoteRegistrationMetaInfo>inRemoteRegisteredEntryclass.- Move
CommandOptionsand back-off timer toRemoteRegisteredEntry.
- The back-off timer is per-prefix-HUB, so it belongs to
RemoteRegisteredEntry.CommandOptionsspecifies the command prefix (such asndn:/localhop/hobo/nfdin #3142) of the HUB, so it needs to be per-prefix-HUB.
So, RemoteRegistrationMetaInfo is also per-prefix-hub object.
- Construct
CommandParametersbefore sending each command, or cache it as part ofRemoteRegisteredEntry.
Constructing it each time is unnecessary.
Storing it as part of RemoteRegisteredEntry breaks the logic, because ControlParameters is not a logic part of RemoteRegisteredEntry.
Updated by Junxiao Shi almost 11 years ago
Reply to note-59:
If both RemoteRegistrationMetaInfo and RemoteRegisteredEntry are per-prefix-HUB, they should be merged into one data structure, otherwise it would suffer from the problem: The distinction between RemoteRegistrationMetaInfo and RemoteRegisteredEntry is unclear.
Updated by Yanbiao Li almost 11 years ago
Reply to note-59:
If both
RemoteRegistrationMetaInfoandRemoteRegisteredEntryare per-prefix-HUB, they should be merged into one data structure, otherwise it would suffer from the problem: The distinction betweenRemoteRegistrationMetaInfoandRemoteRegisteredEntryis unclear.
But RemoteRegistrationMetaInfo is not a part of RemoteRegisteredEntry in logic, and they are very different things and are designed for different purposes. Actually, they work, in logic, separately. The only reason I put a pointer of RemoteRegistrationMetaInfo in RemoteRegisteredEntry is to simplify the implementation of afterHubConnect
Updated by Junxiao Shi almost 11 years ago
commit:a67c852f9d2799146747ad9626d96fa04211a5bf still doesn't explain why back-off timer value is kept in RemoteRegistrationMetaInfo, while the relevant scheduled events are kept in RemoteRegisteredEntry.
Another question is: since RemoteRegistrationMetaInfo is defined as per-prefix-HUB, why is it a shared_ptr in RemoteRegisteredEntry? Why not unique_ptr or a value field (copy)? Copying such a small struct is cheaper, and makes the semantics more understandable.
Updated by Yanbiao Li almost 11 years ago
commit:a67c852f9d2799146747ad9626d96fa04211a5bf still doesn't explain why back-off timer value is kept in
RemoteRegistrationMetaInfo, while the relevant scheduled events are kept inRemoteRegisteredEntry.
Obviously, RefreshTimer and RetryTimer are parts of the state machine (will trigger state switch) which are described in the state machine. But the retry policy is not. No matter how long will you wait before each retry, the state transition on RetryTimer is the same.
Another question is: since
RemoteRegistrationMetaInfois defined as per-prefix-HUB, why is it ashared_ptrinRemoteRegisteredEntry? Why notunique_ptror a value field (copy)? Copying such a small struct is cheaper, and makes the semantics more understandable.
Again, MetaInfo has a longer lifetime and, mostly importantly, it's not a logic part of RemoteRegisteredEntry. I have clarified this on gerrit, redmine and NFD call, the only reason I put a pointer to MetaInfo is RemoteRegisteredEntry is to simplify the implementation of afterHubConnect. If you think it's confusing, I do not mind to change the implementation. If you think I just did not make a clear documentation, you can point out this in gerrit.
Besides, per-prefix-hub means there is only one instance rather than only one pointer. Allowing copying pointers makes the implementation more convenient.
Updated by Junxiao Shi almost 11 years ago
Reply to note-63:
Obviously, RefreshTimer and RetryTimer are parts of the state machine (will trigger state switch) which are described in the state machine.
Agreed.
But the retry policy is not.
Agreed. But what's contained in RemoteRegistrationMetaInfo is not the retry policy.
A retry policy looks like: "the duration before the first retry is 5 seconds; after each unsuccessful retry, the duration before the next retry is 200% of the previous duration, but no greater than 160 seconds".
RemoteRegistrationMetaInfo::m_retryWaitTime field is the state of a retry policy, not the policy itself.
MetaInfo has a longer lifetime
Only a part of RemoteRegistrationMetaInfo requires a longer lifetime than RemoteRegisteredEntry.
RemoteRegistrationMetaInfo::m_retryWaitTime field should not have a longer lifetime.
Updated by Yanbiao Li almost 11 years ago
Reply to note-63:
Obviously, RefreshTimer and RetryTimer are parts of the state machine (will trigger state switch) which are described in the state machine.
Agreed.
But the retry policy is not.
Agreed. But what's contained in
RemoteRegistrationMetaInfois not the retry policy.A retry policy looks like: "the duration before the first retry is 5 seconds; after each unsuccessful retry, the duration before the next retry is 200% of the previous duration, but no greater than 160 seconds".
correct, it's a simplified back-off strategy. And only the RemoteRegistrator knows this policy. 3 arguments, baseRetryWait, maxRetryWait and currentRetryWait, are required to carry out this policy. The first two of them are maintained as RemoteRegistrator's members (as they are the same for any registration), while currentRetryWait, which is dynamic and may be changed many times for each registration, are maintained in RemoteRegistrationMetaInfo.
RemoteRegistrationMetaInfo::m_retryWaitTimefield is the state of a retry policy, not the policy itself.
Yes, and the policy its itself should not be part of RemoteRegistrationMetaInfo. As I clarified, RemoteRegistrationMetaInfo is just a collection of helper information that used to control the registration / unregistration. It only maintains required information, provides interfaces to modify them if required.
At the very beginning, I did not put the current retryWaitTime in RemoteRegistrationMetaInfo. Instead, it's passed as an argument to all related methods. But, after thinking this again and again, I found 2 simple reasons to put it in RemoteRegistrationMetaInfo:
1) curretRetryWait is a necessary argument (helper information) for carrying the retry policy by RemoteRegistrator. To this point, it's similar to ControlParameters and CommandOptions, which are necessary arguments (helper information) for generating registration / unregistration commands RemoteRegistrator (finally handled by m_nfdController). Maintaining currentRetryWait in RemoteRegistrationMetaInfo will not break its logic. Essentially, all information maintained in RemoteRegistrationMetaInfo are directly used by the RemoteRegistrator to control registration / unregistration. While what maintained in RemoteRegisteredEntry is directly used to perform the state machine. The only exception is keeping a pointer to RemoteRegistrationMetaInfo can simplify the implementation of afterHubConnect.
2) All methods that requires a argument of currentRetryWait requires a argument of RemoteRegistrationMetaInfo too. Given we already pass a shared pointer of RemoteRegistrationMetaInfo to those methods, maintaining currentRetryWait in RemoteRegistrationMetaInfo will reduce the cost and make these methods cleaner. Though this gain is not that big, if we can , why not?
MetaInfo has a longer lifetime
Only a part of
RemoteRegistrationMetaInforequires a longer lifetime thanRemoteRegisteredEntry.
RemoteRegistrationMetaInfo::m_retryWaitTimefield should not have a longer lifetime.
Yes, currentRetryWait (i.e. RemoteRegistrationMetaInfo::m_retryWaitTime) do not have to have a longer lifetime, but there is no harm to let it live as long as the RemoteRegistrationMetaInfo. In theory, the lifetime of a currentRetryWait could be much shorter, once some attempt succeeds it will be reset to the initial value. But I do not care so much about this. What I only care about is whether its value is correct when it is used.
Updated by Junxiao Shi almost 11 years ago
Reply to note-65:
2) All methods that requires a argument of currentRetryWait requires a argument of RemoteRegistrationMetaInfo too.
This argument is invalid.
Applying the same argument could lead to: "Every function that requires a SigningInfo requires a KeyChain too", which is confusing.
I think the root cause of all problems is: RemoteRegisteredEntry lifetime is too short.
How about:
- explicitly define a RELEASED state as part of the state machine
- retain an entry with RELEASED state in the map, as long as any field is still needed (in particular, the retry timer during unregistration)
- erase the entry from the map, only after unregistration is successful
With that:
RemoteRegistrationMetaInfois static, and is calculated from RIB and PIB- it contains the prefix to register, the signing identity, and the cost field
- it is per-prefix, and is shared among
RemoteRegisteredEntryobjects of the same prefix
RemoteRegisteredEntrycontains all dynamic information- it contains the state machine, the retry timer,
CommandParameters,CommandOptions - it is per-prefix-HUB
- it contains the state machine, the retry timer,
Updated by Yanbiao Li almost 11 years ago
Reply to note-65:
2) All methods that requires a argument of currentRetryWait requires a argument of RemoteRegistrationMetaInfo too.
This argument is invalid.
Applying the same argument could lead to: "Every function that requires aSigningInforequires aKeyChaintoo", which is confusing.
our case is very different with the above example.
1) KeyChain will use SigningInfo to sign. But in our case, MetaInfo is collection of helper information used by the RemoteRegistrator, while currentRetryWait itself is one of such information.
2) A proper example is: not every function that requires ControlParameters requires a FaceId but we will have such a field in ControlParameters.
3) In our case, every methods in RemoteRegistrator requires a MetaInfo also needs a currentRetryWait, but some of them do not have to accept this as a argument (they will use baseRetryWait instead).
Actually, there are two implementation options:
1) keep some methods accept only a shared pointer to MetaInfo and uses baseRetryWait inside. While let others accept both a shared pointer to MetaInfo and a currentRetryWait.
2) maintain a currentRetryWait in MetaInfo and let all related methods accept only a shared pointer to MetaInfo.
I think the second one is better. It not only reduces the cost of passing an additional argument but also keeps the interfaces cleaner.
I think the root cause of all problems is:
RemoteRegisteredEntrylifetime is too short.
I do not think so. It's not the deign that causes your confusing, but the implementation choice I adopted.
And what I selected at last is the best one, in my opinion, among all that I tried.
Anyway, if you relay dislike it, I do not mind to adopt other implementation options. But currently, I still think my choice is reasonable.
How about:
- explicitly define a RELEASED state as part of the state machine
- retain an entry with RELEASED state in the map, as long as any field is still needed (in particular, the retry timer during unregistration)
- erase the entry from the map, only after unregistration is successful
As mentioned above, there is no design issues but different implementation choices. So there is no need to amend the design that has already been approved and implemented.
With that:
RemoteRegistrationMetaInfois static, and is calculated from RIB and PIB
- it contains the prefix to register, the signing identity, and the cost field
- it is per-prefix, and is shared among
RemoteRegisteredEntryobjects of the same prefix
prefix to register, and cost has already been maintained in ControlParameters,
the signing identity has already been maintained in CommandOptions.
Sotring additional copies of them are redundant.
Most importantly, adding a per-prefix layer makes the design more complex.
RemoteRegisteredEntrycontains all dynamic information
- it contains the state machine, the retry timer,
CommandParameters,CommandOptions- it is per-prefix-HUB
personally, I dislike to put too many things, especially something like ControlParameters and CommandOptions, in RemoteRegisteredEntry, which does nothing than making the concept and design purpose of RemoteRegisteredEntry unclear.
Updated by Junxiao Shi almost 11 years ago
Reply to note-67:
Actually, there are two implementation options:
1) keep some methods accept only a shared pointer to MetaInfo and uses baseRetryWait inside. While let others accept both a shared pointer to MetaInfo and a currentRetryWait.
2) maintain a currentRetryWait in MetaInfo and let all related methods accept only a shared pointer to MetaInfo.I think the second one is better. It not only reduces the cost of passing an additional argument but also keeps the interfaces cleaner.
Having one parameter instead of two, at the cost of stuffing a somewhat irrelevant variable into a struct, does not make the interfaces cleaner.
"The cost of passing an additional argument" is not proven by a benchmark.
It's not the deign that causes your confusing, but the implementation choice I adopted.
Introducing the RemoteRegistrationMetaInfo is a design change.
And what I selected at last is the best one, in my opinion, among all that I tried.
No comparison has been given among different design choices, and the reasons given are unconvincing.
The comparison should cover note-66 design as well.
prefix to register, and cost has already been maintained in ControlParameters,
the signing identity has already been maintained in CommandOptions.
Sotring additional copies of them are redundant.
Both ControlParameters and CommandOptions are per-prefix-HUB due to reason given in note-58.
Prefix to register and the cost are determined from RIB and PIB, and are per-prefix.
adding a per-prefix layer makes the design more complex.
This is needed anyways since remote registration needs to support multi-HUB scenario.
It's beneficial to make the design compatible with roadmap.
I dislike to put too many things, especially something like ControlParameters and CommandOptions, in RemoteRegisteredEntry, which does nothing than making the concept and design purpose of RemoteRegisteredEntry unclear.
The purpose of RemoteRegisteredEntry is: contains per-prefix-HUB states of remote registration procedure.
Under this purpose definition, it's correct to put these in RemoteRegisteredEntry.
Updated by Yanbiao Li almost 11 years ago
Reply to note-67:
Actually, there are two implementation options:
1) keep some methods accept only a shared pointer to MetaInfo and uses baseRetryWait inside. While let others accept both a shared pointer to MetaInfo and a currentRetryWait.
2) maintain a currentRetryWait in MetaInfo and let all related methods accept only a shared pointer to MetaInfo.I think the second one is better. It not only reduces the cost of passing an additional argument but also keeps the interfaces cleaner.
Having one parameter instead of two, at the cost of stuffing a somewhat irrelevant variable into a struct, does not make the interfaces cleaner.
I have clarified the intention of packaging some information into a structure MetaInfo and why currentRetryTime cab be packaged into it. I do not want relate the same thing again and again.
"The cost of passing an additional argument" is not proven by a benchmark.
Just in view of the cost of passing arguments, passing A must not be worse than passing A and passing B. It's as simple as x + y > x. More rigorously, if y is much less than x, x + y may be approximately equal to x. Otherwise, x + y > x.
It's not the deign that causes your confusing, but the implementation choice I adopted.
Introducing the
RemoteRegistrationMetaInfois a design change.
I just package some information, that passed to all related methods as arguments (see patch sets before 19), into a struct (see patch 19). To simplify the access to some fields, I provide some simple interfaces and make the structure a class. That's it. How this implementation simplifications must result in design changes of the state machine? it's far beyond my understanding.
And what I selected at last is the best one, in my opinion, among all that I tried.
No comparison has been given among different design choices, and the reasons given are unconvincing.
The comparison should cover note-66 design as well.
1) Again, what I compared is different implementation choices. I selected the best option in my opinion. But I do not mind switch to other choices if you have reasonable reasons.
2) Again, what causes your confusing is just the implementation choices I adopted, it's obviously unnecessary to make a new design to resolve this issue. And what is mentioned in note-66 makes the design more complex and the definition of RemoteRegisteredEntry unclear.
prefix to register, and cost has already been maintained in ControlParameters,
the signing identity has already been maintained in CommandOptions.
Sotring additional copies of them are redundant.Both
ControlParametersandCommandOptionsare per-prefix-HUB due to reason given in note-58.
Prefix to register and the cost are determined from RIB and PIB, and are per-prefix.adding a per-prefix layer makes the design more complex.
This is needed anyways since remote registration needs to support multi-HUB scenario.
It's beneficial to make the design compatible with roadmap.
1) Again, we have already agreed that current RemoteRegisrator is for one-hub scenario only.
2) Even for multi-hub scenario, most of current design, without the additional per-prefix layer, still work.
I dislike to put too many things, especially something like ControlParameters and CommandOptions, in RemoteRegisteredEntry, which does nothing than making the concept and design purpose of RemoteRegisteredEntry unclear.
The purpose of
RemoteRegisteredEntryis: contains per-prefix-HUB states of remote registration procedure.
Under this purpose definition, it's correct to put these inRemoteRegisteredEntry.
Among some implementation choices, I adopt one I though can simplify the implementation. Some part makes you confusing, then you suggested to amend the design of state machine, to change to definition of RemoteRegisteredEntry to hold more things unrelated to the state machine. Do you really think it's necessary? At least, I think it's completely unnecessary. Though I think I already clarified what makes you confusing, if you do not accept I still do not mind to change the implementation choice, i.e, removing the pointer to MetaInfo from the RemoteRegisteredEntry, or even going back to let all related methods accept ControlParameters, CommandOptions and currentRetryWait again.
Updated by Junxiao Shi almost 11 years ago
Reply to note-69:
The introduction of RemoteRegistrationMetaInfo is causing confusions and the reason is unconvincing.
I'm fine with changing back to accepting multiple parameters on each method.
Updated by Yanbiao Li almost 11 years ago
- File deleted (
remote-state-machine.pdf)
Updated by Yanbiao Li almost 11 years ago
- File deleted (
remote-transition-table.pdf)
Updated by Junxiao Shi almost 11 years ago
Yanbiao posts on http://gerrit.named-data.net/2049 at 20150916 19:27 UTC:
But that change did much more than solving the BUG2413. The design is changed to some extent.
There are two issues that will affect current integration test:
1) there is no "retry" field in config file (which caused configuration error ), this is easy to solve;
2) the shortest identity is selected for registration rather than the longest identity. This needs to change the test logic slightly.
This post is talking about commit:214a1d176f4ccc3e7f5b5f9fb95c54a12ac58944, which solely refs this issue.
I see no discussion in this issue about selecting the shortest identity rather than the longest identity for registration.
If there's a legit reason for that, it should be documented; since it's unrelated to this bug, this change should have its own Redmine issue, and the commit can refs both issues.
Otherwise, the implementation should conform to the existing spec and keep using the longest identity.
Updated by Yanbiao Li almost 11 years ago
see my comments on patch set 18 made on Aug 13 9:49 pm.
you replied my comments but did not post any objection.
Why use shortest identity?
this is what we all agreed on some NFD call (I did not remember the exact date). And I also talked about this on NDN Seminar.
It's unrelated to this issue.
Yes, it is. But the current commit is already far from fixing BUG 2413. Given majority parts are changed, why exclude this.
Updated by Junxiao Shi almost 11 years ago
Bottomline: create an issue with a full justification of the semantics change, and refs that issue in the commit.
Updated by Junxiao Shi almost 11 years ago
20150917 conference call decides a "redesign" issue should be created to document the changes beyond fixing the original bug.
Updated by Yanbiao Li almost 11 years ago
- Related to Feature #3211: Redesign of remote prefix registration added
Updated by Junxiao Shi almost 11 years ago
- Status changed from In Progress to Closed
- % Done changed from 90 to 100
Updated by Junxiao Shi almost 11 years ago
I confirm the bug is fixed in nfd:commit:d7c96360782a1b7f50095aa212c1294fc207115f.
1444054520.506390 INFO: [RibManager] Adding route /localhop/nfd nexthop=263 origin=255 cost=0
1444054520.516880 INFO: [AutoPrefixPropagator] this is a prefix registered by some hub: /localhop/nfd
1444054520.517081 INFO: [AutoPrefixPropagator] redo 1 propagations when new Hub connectivity is built.