Task #3564
closed
Performance profiling
Added by Junxiao Shi about 10 years ago. Updated over 8 years ago.
100%
Description
Profile the performance of NFD forwarder, and understand where the bottlenecks are.
Files
| Screen Shot 2016-03-24 at 4.01.33 PM.png (21 KB) Screen Shot 2016-03-24 at 4.01.33 PM.png | Performance artifact observed as CS reaches full. | John DeHart, 03/24/2016 04:03 PM | |
| expandFunctionsWithInclusiveTimeByDepth.v0.3.py (15.9 KB) expandFunctionsWithInclusiveTimeByDepth.v0.3.py | scripts to generate the profiling report based on gprof callgraph | Chengyu Fan, 04/01/2016 12:14 PM | |
| local-360000-64-udp4-5-5-5-10.profiling.txt (443 KB) local-360000-64-udp4-5-5-5-10.profiling.txt | Example profiling report for nfd 0.4.0. The experiment contains 64 generator pairs. The Interest sending rate is 5ms. Each Interest uses 5 name components, each component contains 5 chars, and the content size is 10B. | Chengyu Fan, 04/01/2016 12:14 PM | |
| inclusiveTime.local-180000-32-udp4-10-5-5-10-Cs0.txt (347 KB) inclusiveTime.local-180000-32-udp4-10-5-5-10-Cs0.txt | Profiling for nfd 0.4.1. It contains 32 generator pairs. The Interest sending rate is 10ms. Each Interest uses 5 name components, each component contains 5 chars, and the content payload is 10B. One client sends 180k Int in total. CS=0 | Chengyu Fan, 04/04/2016 01:25 PM | |
| gprof.local-180000-32-udp4-10-5-5-10-Cs0.txt (2.25 MB) gprof.local-180000-32-udp4-10-5-5-10-Cs0.txt | gprof report for nfd 0.4.1 | Chengyu Fan, 04/05/2016 12:25 PM | |
| callgrind.nfd.local-225000-32-udp4-8-5-5-10.out (2.13 MB) callgrind.nfd.local-225000-32-udp4-8-5-5-10.out | callgrind report for NFD 0.4.1. Test contains 32 client-server pairs. Clients send an Interests every 8ms. This test has lots of packets lost | Chengyu Fan, 04/25/2016 10:25 PM | |
| callgrind.nfd.no-gprof-flag.225000-32-udp4-8-5-5-10.out (2.02 MB) callgrind.nfd.no-gprof-flag.225000-32-udp4-8-5-5-10.out | callgrind report for face-system without gprof flags. Test contains 16 client-server pairs. Clients send an Interests every 8ms. Content payload is 10B. This test has lots of packets lost | Chengyu Fan, 04/27/2016 09:02 AM |
{kind=link}
 Updated by Junxiao Shi about 10 years ago
Updated by Junxiao Shi about 10 years ago
The issue description is same as #1621, but we need a new profiling for NFD 0.4.1 as the baseline when we prepare for improvements.
A useful report should expand the call graph to one level deeper than an NFD function, but should not go into STL/Boost/ndn-cxx.
Specifically, if the call graph is represented as a tree, a tree node should be expanded if its parent contains a descendant that is an NFD function, otherwise it should not be collapsed.
Inclusive time should be reported on each node.
For example, if we have an NFD function like this:
std::set<Name> g_names;
std::list<shared_ptr<NfdStruct3>> g_entries;
void nfdFunction1(const Name& name)
{
nfdFunction2(name);
g_names.insert(name);
g_entries.push_back(make_shared<NfdStruct3>());
}
The report should contain:
- inclusive time of
nfdFunction1 - inclusive time of
nfdFunction2, and further expanding from there - inclusive time of
g_names.insert, without further expanding; this callsName::comparein ndn-cxx but it's not an NFD function - inclusive time of
g_entries.push_back - inclusive time of
NfdStruct3constructor, which is called byg_entries.push_backand it's an NFD function;make_sharedandstd::listshould not be shown
 Updated by Davide Pesavento about 10 years ago
Updated by Davide Pesavento about 10 years ago
I disagree with not investigating ndn-cxx functions. If a bottleneck in ndn-cxx affects the forwarder, we should fix it by either not using that function or by optimizing it.
Updated by Junxiao Shi about 10 years ago
Reply to note-2:
The rationale of not investigating ndn-cxx functions is to separate the concerns, and keep the report relatively short.
The example in note-1 expands to:
+ 5000ms nfdFunction1
|-+ 3000ms nfdFunction2
| \-- (omitted)
|-+ 1000ms g_names.insert
\-+ 1000ms g_entries.push_back
\-- 900ms NfdStruct3 constructor
This reflects the time spent within g_names.insert, which includes STL std::set operations and ndn-cxx Name::compare.
If g_names.insert line is suspected to be a bottleneck, std::set and Name::compare can be profiled separately in a mini program, which is much easier to analysis.
 Updated by John DeHart about 10 years ago
Updated by John DeHart about 10 years ago
Since it came up in the nfd call today,
I would like to comment on the ways to control the rate of traffic in the ONL performance tests.
The test setup uses a script, mkAll.sh, to configure the test to be run.
This script takes several arguments:
$ ./mkAll.sh
Usage: ./mkAll.sh [options] <count> <proto> <interval> <num name components> <component length>
Options:
[--local] - use start scripts to run local (../NFD_current_git_optimized/usr/local/bin/) versions of nfd and nrd
[--installed] - use start scripts to run the installed (based on PATH) versions of nfd and nrd
The count argument tells it how many producer/consumer pairs to use in the test.
The proto argument tells it whether to use udp or tcp faces.
The interval argument is fed to ndn-traffic as its interest generation interval.
The last two arguments control the number and size of the name components used.
So, we have control over how many streams of interests we will send and the interval between the interests in those individual streams.
With the current ONL topology being used the practical limit on the number of producer/consumer pairs is 64.
The practical limit on the interval is 1 ms.
Given that, we can approach an interest rate of 64K/sec.
I think that will give us a good environment for testing improvements in nfd performance for some time.
As we approach the limit, I will work on a new ONL topology to test up to and beyond our goal of 100K/sec.
Updated by John DeHart about 10 years ago
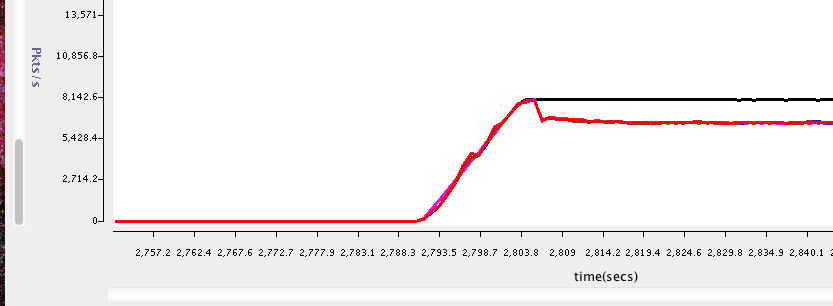
I have also added a screen shot of an artifact that I have noticed.
This artifact occurs when the CS reaches full. What we see is an approximately
20% decrease in performance.
This is an observation that may not be obvious from profiling data.
 Updated by Chengyu Fan about 10 years ago
Updated by Chengyu Fan about 10 years ago
- Status changed from New to In Progress
Updated by Chengyu Fan about 10 years ago
- % Done changed from 0 to 40
Comments to note-3:
We'd better use percentage time, instead of the inclusive milliseconds spent in each function and its children.
+ 100 nfdFunction1
|-+ 30 nfdFunction2
| \-- (omitted)
|-+ 30 g_names.insert
\-+ 40 g_entries.push_back
\-- 35 NfdStruct3 constructor
Questions regarding to the report:
Some functions may have several parent functions.
For example, A->C, B->C. Assuming that A and its children takes 30% of the time, B and its children takes 20%. For function C, it takes 30% time in total. 70% of the time is from A, the rest is from B.
In this case, are we showing the graph by dividing the percentage time?
+ 30% A
|-+ 21% C
+ 20% B
|-+ 9% C
Updated by Junxiao Shi about 10 years ago
Reply to note-7:
There's no conflict between "inclusive time" and "percentage".
"Inclusive time" is in contrast to "exclusive time".
"Percentage" and "milliseconds" are choices of time unit, and either is fine.
A function with multiple callers should be reported separately under each caller.
Updated by Chengyu Fan about 10 years ago
- File expandFunctionsWithInclusiveTimeByDepth.v0.3.py expandFunctionsWithInclusiveTimeByDepth.v0.3.py added
- File local-360000-64-udp4-5-5-5-10.profiling.txt local-360000-64-udp4-5-5-5-10.profiling.txt added
- % Done changed from 40 to 90
These example profiling report file is for NFD 0.4.0.
I will upload another one for NFD 0.4.1
Updated by Chengyu Fan about 10 years ago
- File inclusiveTime.local-180000-32-udp4-10-5-5-10-Cs0.txt inclusiveTime.local-180000-32-udp4-10-5-5-10-Cs0.txt added
- Status changed from In Progress to Feedback
- % Done changed from 90 to 100
The uploaded report is for 0.4.1. This test disabled the Content Store (by set CS = 0).
From the report, we can easily find that the Data forwarding pipeline takes much less time 17% vs 48%.
48.40 nfd::face::LinkService::receiveInterest(ndn::Interest const&) [8]
17.10 nfd::face::LinkService::receiveData(ndn::Data const&) [21]
The PIT in general is slow (PIT is ):
+ 12.49 nfd::Pit::findOrInsert(ndn::Interest const&, bool) [25]
|- 10.72 nfd::NameTree::lookup(ndn::Name const&) [28]
According to the gprof flat report (contains the exclusive time for each function), nfd::face::GenericLinkService::assignSequences itself is one of the main contributor: 14.14%.
We need results of task #3567 as the baseline. Currently it still contains a lot of modules in the report.
I also need the feedback from the profiling results for NFD. Is the format good to read? What else do you want it to show?
Updated by Junxiao Shi about 10 years ago
Question on note-10 report:
I see that nfd::face::GenericLinkService::assignSequences(std::vector<ndn::lp::Packet, std::allocator<ndn::lp::Packet> >&) is nested under ndn::Block::Block(ndn::Block const&), indicating that Block copy constructor calls assignSequences.
However, this is impossible because a ndn-cxx function cannot call a NFD function unless a function pointer is passed as an argument, but Block copy constructor does not take a function pointer.
Can you explain why this is observed?
Updated by Davide Pesavento about 10 years ago
Junxiao Shi wrote:
I see that
nfd::face::GenericLinkService::assignSequences(std::vector<ndn::lp::Packet, std::allocator<ndn::lp::Packet> >&)is nested underndn::Block::Block(ndn::Block const&), indicating thatBlockcopy constructor callsassignSequences.
However, this is impossible because a ndn-cxx function cannot call a NFD function unless a function pointer is passed as an argument, butBlockcopy constructor does not take a function pointer.
Yep that's pretty weird indeed.
Btw there's an unnecessary copy in this push_back: https://github.com/named-data/NFD/blob/0de23a29c5c46d7134d03361244fb913159e750c/daemon/face/generic-link-service.cpp#L116. Moving the argument pkt would be an easy improvement.
Updated by Chengyu Fan about 10 years ago
- File gprof.local-180000-32-udp4-10-5-5-10-Cs0.txt gprof.local-180000-32-udp4-10-5-5-10-Cs0.txt added
Junxiao Shi wrote:
Question on note-10 report:
I see that
nfd::face::GenericLinkService::assignSequences(std::vector<ndn::lp::Packet, std::allocator<ndn::lp::Packet> >&)is nested underndn::Block::Block(ndn::Block const&), indicating thatBlockcopy constructor callsassignSequences.
However, this is impossible because a ndn-cxx function cannot call a NFD function unless a function pointer is passed as an argument, butBlockcopy constructor does not take a function pointer.
Can you explain why this is observed?
You are right. But I don't know how to explain it. As shown in the profile file gprof.local-180000-32-udp4-10-5-5-10-Cs0.txt ...
0.00 0.00 206/504025578 std::__shared_count<(__gnu_cxx::_Lock_policy)2>::__shared_count<ndn::SimpleTag<ndn::lp::CachePolicy, 12>, std::allocator<ndn::Sim
pleTag<ndn::lp::CachePolicy, 12> >, ndn::lp::CachePolicy>(std::_Sp_make_shared_tag, ndn::SimpleTag<ndn::lp::CachePolicy, 12>*, std::allocator<ndn::SimpleTag<ndn::lp::CachePolicy, 1
2> > const&, ndn::lp::CachePolicy&&) [447]
1.24 0.00 16847786/504025578 std::vector<ndn::Block, std::allocator<ndn::Block> >::operator=(std::vector<ndn::Block, std::allocator<ndn::Block> > const&) <cy
cle 3> [73]
35.94 0.00 487177586/504025578 ndn::Block::Block(ndn::Block const&) [17]
[24] 14.1 37.18 0.00 504025578 nfd::face::GenericLinkService::assignSequences(std::vector<ndn::lp::Packet, std::allocator<ndn::lp::Packet> >&) [24]
That means ndn::Block::Block(ndn::Block const&) called assignSequences 487177586 times. The gprof docs [[https://sourceware.org/binutils/docs/gprof/Implementation.html]] do not explain the details.
However, the profiling scripts use c++0x as the compiler (ONL machines does not support c++11), not sure if it causes such issue.
export CXXFLAGS="$CXXFLAGS -O2 -pg -g -std=c++0x -pedantic -Wall"
I will do two things:
- use another profiling tool (e.g, callgrind) to check if they produce reports with the same issue;
- Use c++11 on local machines to check if this issue still exists.
Any suggestions?
Updated by Davide Pesavento about 10 years ago
Yes please, try with callgrind and see if it exhibits the same behavior.
Updated by Chengyu Fan about 10 years ago
Davide Pesavento wrote:
Yes please, try with callgrind and see if it exhibits the same behavior.
I have tried both.
Neither of them produces reports with the same issue.
In another test, I used an older OS (ubuntu 12.04), which has c++0x as the compiler, as the intermediate router. The gprof report did show assignSequences() is called by ndn::Block::Block in this case.
I have emailed John to ask if he can upgrade the gcc. Otherwise, we have to use callgrind or other tools.
Updated by John DeHart about 10 years ago
I am working on upgrading the compilers on ONL but am running into trouble building ndn-cxx when I do.
When I upgrade to anything beyond gcc-4.6 and g++4.6 waf fails to configure ndn-cxx
because of problems with CryptoPP.
Here is what I am seeing (I've also tried this with 4.8 and 4.9. I'm on Ubuntu 12.04):
jdd@pc2core02:~/NFD_ONL_Installed_Latest_git/0.4.1/ndn-cxx$ gcc --version
gcc (Ubuntu/Linaro 4.7.3-2ubuntu1~12.04) 4.7.3
Copyright (C) 2012 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
jdd@pc2core02:~/NFD_ONL_Installed_Latest_git/0.4.1/ndn-cxx$ g++ --version
g++ (Ubuntu/Linaro 4.7.3-2ubuntu1~12.04) 4.7.3
Copyright (C) 2012 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
jdd@pc2core02:~/NFD_ONL_Installed_Latest_git/0.4.1/ndn-cxx$ ./waf configure
Setting top to : /users/jdd/NFD_ONL_Installed_Latest_git/0.4.1/ndn-cxx
Setting out to : /users/jdd/NFD_ONL_Installed_Latest_git/0.4.1/ndn-cxx/build
Building static library : no
Building shared library : yes
Checking for 'g++' (C++ compiler) : /usr/bin/g++
Checking supported CXXFLAGS : -std=c++11
Checking supported CXXFLAGS : -O2 -g -pedantic -Wall -Wextra -Wno-unused-parameter -Wno-missing-field-initializers
Checking for std::is_default_constructible : yes
Checking for std::is_nothrow_move_constructible : yes
Checking for std::is_nothrow_move_assignable : yes
Checking for friend typename-specifier : yes
Checking for override and final specifiers : yes
Checking for std::to_string : yes
Checking for std::vector::insert with const_iterator : no
Checking for program 'doxygen' : /usr/bin/doxygen
Checking for program 'tar' : /bin/tar
Checking for program 'sphinx-build' : /usr/bin/sphinx-build
Checking for program 'sh' : /bin/sh
Checking for library pthread : yes
Checking for library rt : yes
Checking for function getpass : yes
Checking for rtnetlink : yes
Checking for program 'pkg-config' : /usr/bin/pkg-config
Checking for 'sqlite3' : yes
Checking Crypto++ lib : 5.6.1
Checking if CryptoPP library works : no
Checking if CryptoPP library works : no
CryptoPP is present, but is not usable
(complete log in /users/jdd/NFD_ONL_Installed_Latest_git/0.4.1/ndn-cxx/build/config.log)
jdd@pc2core02:~/NFD_ONL_Installed_Latest_git/0.4.1/ndn-cxx$
I'm sure I'm missing something simple. Any suggestions?
Is there a different version of CryptoPP I need to install?
Updated by Davide Pesavento about 10 years ago
Most likely you need to recompile cryptopp with the new compiler. You might have the same problem with other C++ libraries such as boost.
Until GCC 5 there was no ABI stability guarantee across different compiler versions when building in C++11 mode. And that is the problem I think (well, mine is just an educated guess since waf output doesn't really tell what's going on, try attaching build/config.log).
Isn't there an Ubuntu 14.04 machine that can be used? That would be far simpler than upgrading the compiler on an older Ubuntu release.
Updated by John DeHart about 10 years ago
Davide Pesavento wrote:
Most likely you need to recompile cryptopp with the new compiler. You might have the same problem with other C++ libraries such as boost.
Until GCC 5 there was no ABI stability guarantee across different compiler versions when building in C++11 mode. And that is the problem I think (well, mine is just an educated guess since waf output doesn't really tell what's going on, try attaching
build/config.log).Isn't there an Ubuntu 14.04 machine that can be used? That would be far simpler than upgrading the compiler on an older Ubuntu release.
Yes, I am recognizing that that may be the root of the problem. It is probably time to upgrade the OS on ONL machines.
We have tried to keep them rather uniform and it is always an awkward time to do a massive upgrade.
But maybe I can come up with an interim solution.
Updated by John DeHart about 10 years ago
I have emailed Chengyu a new ONL topology file that should use an upgraded
machine as the central router. This should give him a machine that
runs Ubuntu 14.04 and has gcc version 4.8.4 which supports std=c++11
Updated by Chengyu Fan about 10 years ago
- % Done changed from 100 to 90
Sorry my gmail hided the updates messages.
Some quick updates:
I have generated the gprof report by using the latest topology.
However, my script to produce the tree-like report has bugs to handle the cycle (A-B-C-A).
I will modify the script and upload the report.
Updated by Chengyu Fan about 10 years ago
- File callgrind.nfd.local-225000-32-udp4-8-5-5-10.out callgrind.nfd.local-225000-32-udp4-8-5-5-10.out added
This test is done using callgrind.
I did the tests on ONL. 16 Physical client-server node pairs communicate through a central node.
The test uses 32 traffic generator client-server pairs, 5 name components, and each component contains 5 chars.
In the test, each client sends an Interest every 8ms, and the NFD drops most of the Interests. The content payload is 100 Bytes. People can use KCachegrind to view the call graph.
Updated by Chengyu Fan about 10 years ago
- File callgrind.nfd.no-gprof-flag.225000-32-udp4-8-5-5-10.out callgrind.nfd.no-gprof-flag.225000-32-udp4-8-5-5-10.out added
uploaded the callgrind report that generated without gprof flag.
Updated by Chengyu Fan about 10 years ago
Here are the findings in the callgrind report. In 5-19-16's NFD call, we decide to use TCMalloc for the benchmark, and propose new design for content store.
In general, data processing spends more time than Interest processing:
inclusive time for GenericLinkService::decodeData() and GenericLinkService::decodeInterest() : 51.11% vs. 41.13%- GenericLinkService::decodeData() as a whole spends 3% of the time
- GenericLinkService::decodeInterest() as a whole spends 1.8% of the time
nfd::cs as a whole module is time-consuming, already confirmed by experiments (simply set cs=0, can double the number of Interests sent)
- The major contributor is nfd::cs::EntryImpl::operator<(nfd::cs::EntryImpl const&) const, its inclusive time is 58.07%. Its ancestors, nfd::cs::Cs::find() from onIncomingInterest(), nfd::cs::Cs::insert() from onIncomingData() takes 25.74% and 42.07% respectively.
- ndn::Name::compare(unsigned long, unsigned long, ndn::Name const&, …) as a whole takes 40% (propagated from cs::EntryImpl::operator< …), and its child ndn::name::Component::compare() uses 11.48%.
Another branch of the call graph is PIT. nfd::Pit::findOrInsert() takes 12.89% of the time. Under this branch, a lot of time spent on ndn-cxx library. ndn::Name::wireEncode() takes 6.88%. ndn::Name::getSubName() takes another 2.78%.
Updated by Chengyu Fan almost 10 years ago
Below are the benchmark results for NFD and the face-system with TCMalloc library. For all the tests, the content payload is 10B. According to the results, using TCMalloc library does improve the performance, but not very much. The CS is still the major contributor to the bad performance.
1. face-system
+------------------+------+-----+-----+
| #name components | 25 | 5 | 1 |
+------------------+------+-----+-----+
| with TCMalloc | 37K | 43K | 46K |
+------------------+------+-----+-----+
| w/o TCMalloc | 33K | 37K | 38K |
+------------------+------+-----+-----+
2. NFD with CS=65536
+------------------+-------+-------+-------+
| #name components | 25 | 5 | 1 |
+------------------+-------+-------+-------+
| with TCMalloc | 2.4K | 6.8K | 9.5K |
+------------------+-------+-------+-------+
| w/o TCMalloc | 2.3K | 6K | 8.6K |
+------------------+-------+-------+-------+
3. NFD with CS=0
+------------------+-------+------+------+
| #name components | 25 | 5 | 1 |
+------------------+-------+------+------+
| with TCMalloc | 6.5K | 17K | 22K |
+------------------+-------+------+------+
| w/o TCMalloc | 5.5K | 15k | 17K |
+------------------+-------+------+------+
Updated by Junxiao Shi almost 10 years ago
note-24 indicates there's only minor improvement from changing the allocator, but it's certainly worth doing.
We should also start working on #3610 and other profilings.
Updated by Davide Pesavento over 8 years ago
- Category deleted (
Integration Tests) - Status changed from Feedback to Closed
- % Done changed from 90 to 100